Nimbus: Release Trigger Workflow Platform
Overview
Nimbus explores how modern platforms safely evolve configuration in production. Rather than treating configuration as editable settings, Nimbus treats configuration changes as governed releases. Proposals move through a structured workflow (validation, approval, application) before being atomically promoted to live systems.
The project demonstrates how backend architecture enforces correctness under concurrent change, how real-time systems propagate state without disruption, and how cloud infrastructure enables safe platform evolution at scale.
Why This Matters
Configuration management in production systems is deceptively complex. A small change like font size or background color can affect thousands of users. Traditional approaches (edit a file, redeploy) don't work when multiple people propose changes at the same time. What if two engineers propose changes simultaneously? What if one change conflicts with another? How do you rollback safely?
Nimbus explores these questions by building a system where configuration changes are:
- Immutable and versioned (never edited, only created)
- Promoted through workflow (validated, approved, applied)
- Atomically activated (all-or-nothing state transitions)
- Safely rolled back (revert to any previous version instantly)
What I'll Learn
By building Nimbus, I'll understand:
Architecture and Systems Design:
- How to model complex workflows as state machines
- How to reason about concurrent state transitions
- How to detect and handle conflicts safely
- How backend decisions directly impact user experience
Backend Patterns:
- Async-first request handling in production
- Atomic transactions for correctness
- Event-driven architecture with message queues
- Real-time communication without polling
Infrastructure and Deployment:
- Containerizing applications with Docker
- Deploying to cloud platforms (Cloud Run)
- Managing persistence (PostgreSQL)
- Real-time messaging patterns (SSE, pub/sub)
Full-Stack Integration:
- How frontend and backend communicate asynchronously
- How infrastructure decisions enable architecture
- How to design systems that fail safely
Core Idea
Configuration is immutable. When you want to change something, you create a new configuration version. That version moves through a workflow:
Only one configuration version can be active at a time. Before promotion, the system detects conflicts: "Did another change become active while I was waiting?" If so, the proposal fails safely rather than silently overwriting.
Architecture Walkthrough
To understand how this works, let's trace a single configuration proposal through the system.
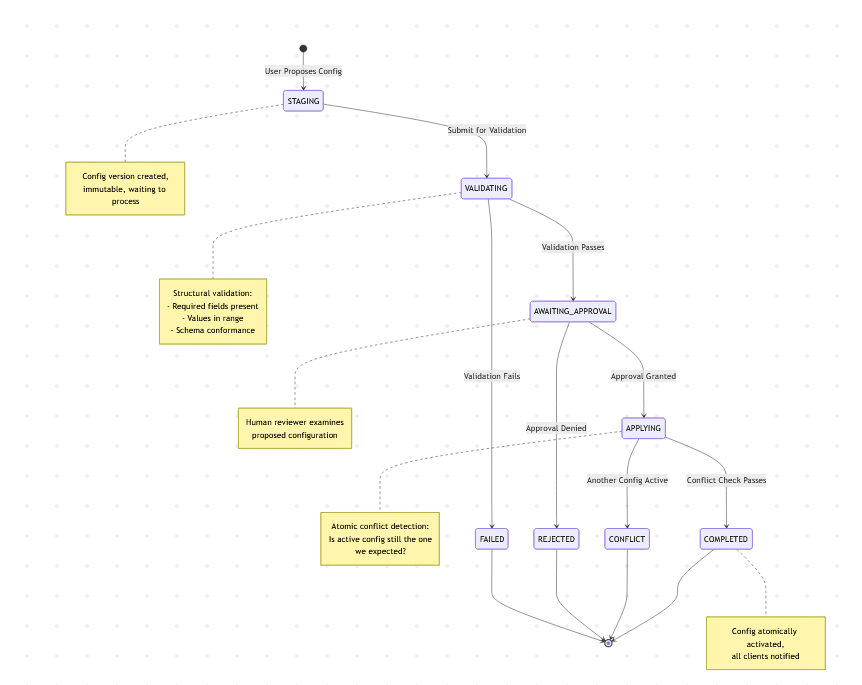
The Scenario
A user wants to change a UI parameter. They propose a new configuration version. The system must:
- Validate that the configuration is structurally correct
- Wait for human approval
- Check for conflicts (did another version become active?)
- Atomically promote it to active
- Notify all clients of the change
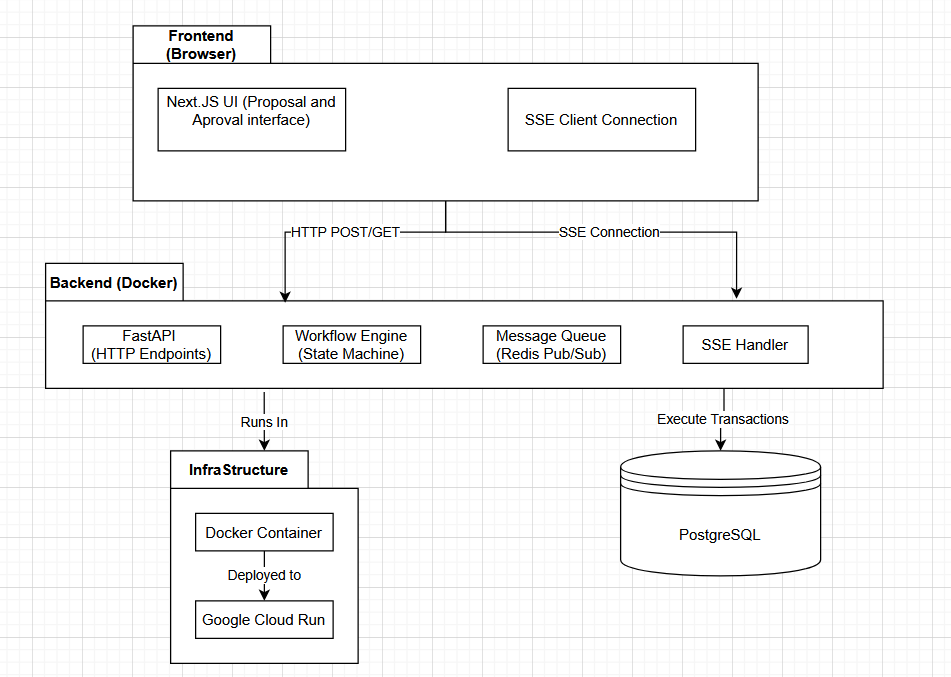
How Data Flows Through the System
Step 1: User Proposes Configuration
The user submits a proposal through the Next.js frontend. This is sent to the FastAPI backend via HTTP POST.
The backend receives the proposal and creates a workflow instance in the database. The configuration is stored as a new immutable version (V5, for example). The workflow state is set to STAGING.
At this point, nothing is live. The proposal exists in the database, waiting to be processed.
Step 2: Validation
The workflow engine transitions the state to VALIDATING.
The backend performs checks:
- Does the configuration have all required fields?
- Are the values within acceptable ranges?
- Does it conform to the schema?
This is deterministic. The same configuration always produces the same validation result.
Once validation completes, the state transitions to AWAITING_APPROVAL.
Step 3: Real-Time Updates to Frontend
While all this is happening, how does the frontend know the workflow is progressing?
The frontend maintains a Server-Sent Events (SSE) connection to the backend. When the workflow engine completes a state transition, it publishes an event to a message queue:
An SSE handler in the backend subscribes to this message queue. When the event arrives, it broadcasts to all connected frontend clients:
The frontend receives this and updates the UI in real-time. The user sees the progress without polling or refreshing.
Why use a message queue instead of broadcasting directly? Because if the backend crashes, the message queue preserves the event. When a new backend instance starts, it can subscribe and continue broadcasting without losing information. The workflow engine and the SSE broadcaster are decoupled.
Step 4: Human Approval
The workflow waits in AWAITING_APPROVAL state. A human reviewer examines the proposed configuration and approves or rejects it.
The frontend shows an approval interface. When the reviewer clicks "Approve," the frontend sends a request to the backend.
The backend transitions the workflow to APPLYING.
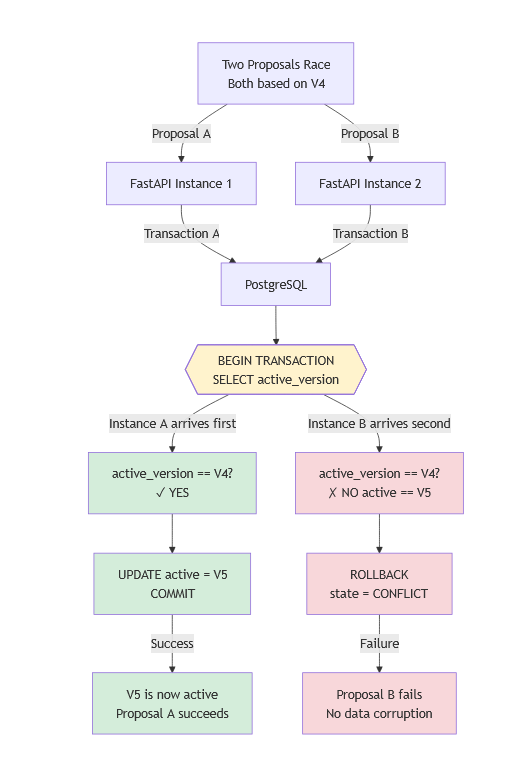
Step 5: Conflict Detection (The Critical Part)
This is where optimistic concurrency control happens.
At the moment the user proposed V5, the active configuration was V4. The proposal says "I'm promoting from V4 to V5."
But what if, while we were validating and waiting for approval, someone else's configuration (V6) became active?
When the workflow engine tries to apply V5, it executes an atomic transaction in PostgreSQL:
This entire operation is atomic. Either:
- V4 is still active, and V5 becomes active (success)
- V4 is not active (V6 is), and the transaction aborts (conflict)
No data corruption. No silent overwrites. The system fails safely.
Step 6: Config Activation and Client Updates
If the transaction succeeded, V5 is now active.
The workflow engine publishes another event to the message queue:
Two SSE handlers receive this:
- Workflow handler: Broadcasts to the approval UI, confirming the deployment succeeded
- Config handler: Broadcasts to all live app clients, notifying them a new configuration is active
Live app clients receive this notification. Instead of refreshing the page (which would destroy user state), they:
- Fetch the new configuration from an endpoint
- Hot-swap it into the running application
- Continue without interruption
The user sees the change immediately, without losing context or scrolling position.
Tech Stack
PostgreSQL (Database)
Configuration versioning requires reliable atomic transactions. When two proposals race to become active, PostgreSQL's ACID (Atomicity, Consistency, Isolation, Durability) guarantees ensure exactly one succeeds and the other fails safely. The BEGIN TRANSACTION ... COMMIT blocks make it impossible to have partial state transitions.
Other databases could store versions, but PostgreSQL's transaction isolation ensures correctness under concurrent load. This is non-negotiable for a system managing state transitions.
What it stores:
- Configuration versions (immutable)
- Workflow instances (state, timestamps, approver info)
- Active configuration pointer
FastAPI and Python (Backend)
The backend needs to handle multiple concurrent requests efficiently. While validating one proposal, approving another, and applying a third, it should remain responsive.
FastAPI is built async-first. Requests don't block each other. While the engine waits for validation to complete or approval to arrive, it can handle other requests. This is critical under load.
Alternatives:
- Flask is simpler but synchronous by default. Requests would queue behind each other.
- Django is full-featured but heavyweight for this scope.
What it does:
- Accepts configuration proposals via HTTP
- Implements the workflow state machine
- Executes conflict detection (the atomic transaction)
- Publishes events to the message queue
- Handles SSE connections for real-time updates
Next.js (Frontend)
The frontend needs to be interactive (show forms, display workflow progress) and connected (receive real-time updates via SSE).
Next.js provides:
- React for interactive UI
- Built-in API routes (lightweight backend helpers, if needed)
- Integrated deployment (no separate server setup)
- Hot module replacement for development
You could use plain React, but then you would need a separate server for hosting and deployment would be more complex. Next.js bundles this together, keeping focus on the actual learning goal: understanding workflow architecture, not DevOps.
What it does:
- Displays configuration proposal form
- Shows workflow state in real-time (via SSE)
- Provides approval interface
- Maintains SSE connection to backend
Server-Sent Events (SSE)
SSE instead of polling (frontend asks "are you done yet?" every second) is wasteful and slow.
WebSocket provides bidirectional communication, but the frontend only needs to receive updates, not send them through SSE. The frontend already has REST endpoints for proposing and approving. One-way communication is sufficient and simpler.
SSE is:
- One-way (server pushes to client)
- Built on HTTP (works through proxies)
- Simple to implement
- Perfect for this use case
What it does:
- Delivers workflow state changes to the approval UI
- Delivers configuration activation events to live app clients
- Maintains persistent connection without polling overhead
Message Queue (Redis Pub/Sub)
Decoupling the workflow engine from SSE is critical. If the FastAPI backend crashes, SSE connections drop. Clients lose real-time updates. If the engine and SSE broadcaster were tightly coupled, you would lose state during restarts.
By publishing to a message queue first:
- Workflow engine publishes: "This happened"
- SSE handler subscribes to the queue
- If SSE handler crashes, a new one picks up where it left off
- Engine is decoupled from transport layer
This is architectural resilience.
Docker and Google Cloud Run (Infrastructure)
Docker packages the entire application (code, dependencies, configuration) into a single image. That image runs identically on your laptop, in CI/CD, and in production. No "it works on my machine" problems.
Cloud Run is serverless container hosting. You push a Docker image, it runs. You pay only for actual execution time, making it perfect for low-traffic personal projects. It scales automatically if traffic spikes. You don't manage servers or infrastructure.
Alternatives:
- EC2: Full server management, overkill for this scope
- Kubernetes: Orchestration complexity, unnecessary here
- Heroku: Easier than Cloud Run but more expensive
- Cloud Run: Serverless, cheap, scales automatically
Status
Designed. Ready for work.
Architecture, data flow, and tech stack are documented and understood. Implementation can begin with:
- Backend API structure and workflow state machine
- PostgreSQL schema for versioning and state tracking
- Frontend proposal and approval UI
- Real-time SSE integration
- Conflict detection and atomic transactions
What This Sets Up
Nimbus establishes the control plane foundation. How to safely manage configuration changes. Once complete, it becomes the governance layer for Murmur (the runtime simulation), which then integrates into Zephyr (the complete platform where architecture decisions visibly reshape behavior).